其中有些题目是刷到知乎上一个人整理的,感觉挺好的。但是当初没有保存地址(图片上有水印,可以去搜一下)
Spark知识点
spark有哪些组件
master:管理集群和节点,不参与计算。
worker:计算节点,进程本身不参与计算,和master汇报。
Driver:运行程序的main方法,创建spark context对象。
spark context:控制整个application的生命周期,包括dagsheduler和task scheduler等组件。
client:用户提交程序的入口。
对于 Spark 中的数据倾斜问题你有什么好的方案?
Spark 数据倾斜的几种场景以及对应的解决方案,包括避免数据源倾斜,调整并行度,使用自定义 Partitioner,使用 Map 侧 Join 代替 Reduce 侧 Join(内存表合并),给倾斜 Key 加上随机前缀等。
什么是数据倾斜
对 Spark/Hadoop 这样的大数据系统来讲,数据量大并不可怕,可怕的是数据倾斜。数据倾斜指的是,并行处理的数据集中,某一部分(如 Spark 或 Kafka 的一个 Partition)的数据显著多于其它部分,从而使得该部分的处理速度成为整个数据集处理的瓶颈(木桶效应)。
数据倾斜是如何造成的
在 Spark 中,同一个 Stage(阶段) 的不同 Partition 可以并行处理,而具有依赖关系的不同 Stage 之间是串行处理的。假设某个 Spark Job 分为 Stage 0和 Stage 1两个 Stage,且 Stage 1依赖于 Stage 0,那 Stage 0完全处理结束之前不会处理Stage 1。而 Stage 0可能包含 N 个 Task,这 N 个 Task 可以并行进行。如果其中 N-1个 Task 都在10秒内完成,而另外一个 Task 却耗时1分钟,那该 Stage 的总时间至少为1分钟。换句话说,一个 Stage 所耗费的时间,主要由最慢的那个 Task 决定。由于同一个 Stage 内的所有 Task 执行相同的计算,在排除不同计算节点计算能力差异的前提下,不同 Task 之间耗时的差异主要由该 Task 所处理的数据量决定。
具体解决方案
调整并行度分散同一个 Task 的不同 Key
Spark 在做 Shuffle 时,默认使用 HashPartitioner(非 Hash Shuffle ???)对数据进行分区。如果并行度设置的不合适,可能造成大量不相同的 Key 对应的数据被分配到了同一个 Task 上,造成该 Task 所处理的数据远大于其它 Task,从而造成数据倾斜。如果调整 Shuffle 时的并行度,使得原本被分配到同一 Task 的不同 Key 发配到不同 Task 上处理,则可降低原 Task 所需处理的数据量,从而缓解数据倾斜问题造成的短板效应。下图左边绿色框表示 kv 样式的数据,key 可以理解成 name。可以看到 Task0 分配了许多的 key,调整并行度,多了几个 Task,那么每个 Task 处理的数据量就分散了。
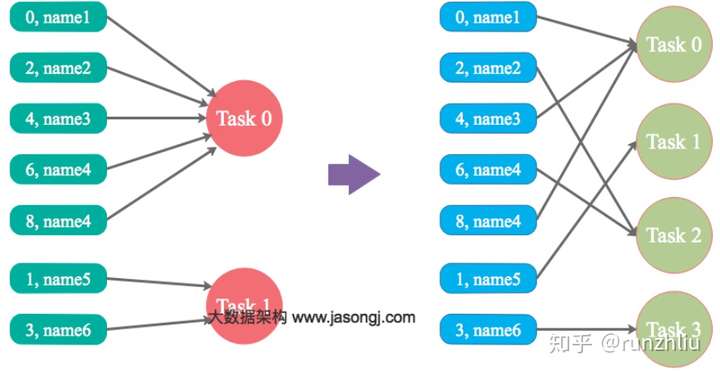
自定义Partitioner
使用自定义的 Partitioner(默认为 HashPartitioner),将原本被分配到同一个 Task 的不同 Key 分配到不同 Task,可以拿上图继续想象一下,通过自定义 Partitioner 可以把原本分到 Task0 的 Key 分到 Task1,那么 Task0 的要处理的数据量就少了。
将 Reduce 侧 Join 转变为 Map 侧 Join
通过 Spark 的 Broadcast 机制,将 Reduce 侧 Join 转化为 Map 侧 Join,避免 Shuffle 从而完全消除 Shuffle 带来的数据倾斜。可以看到 RDD2 被加载到内存中了。
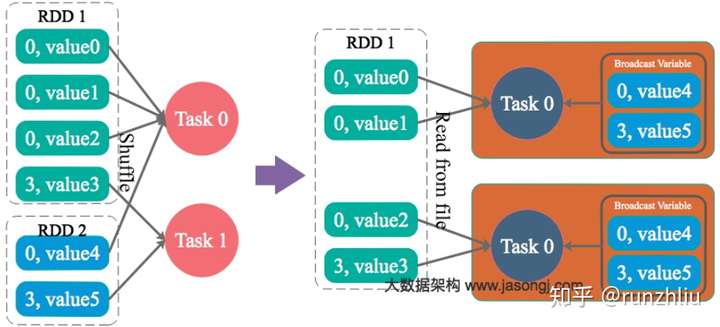
为 skew 的 key 增加随机前/后缀
为数据量特别大的 Key 增加随机前/后缀,使得原来 Key 相同的数据变为 Key 不相同的数据,从而使倾斜的数据集分散到不同的 Task 中,彻底解决数据倾斜问题。Join 另一则的数据中,与倾斜 Key 对应的部分数据,与随机前缀集作笛卡尔乘积,从而保证无论数据倾斜侧倾斜 Key 如何加前缀,都能与之正常 Join。
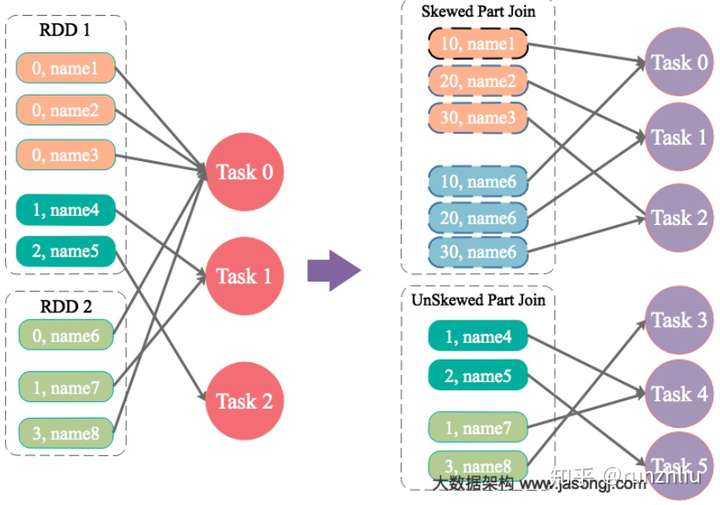
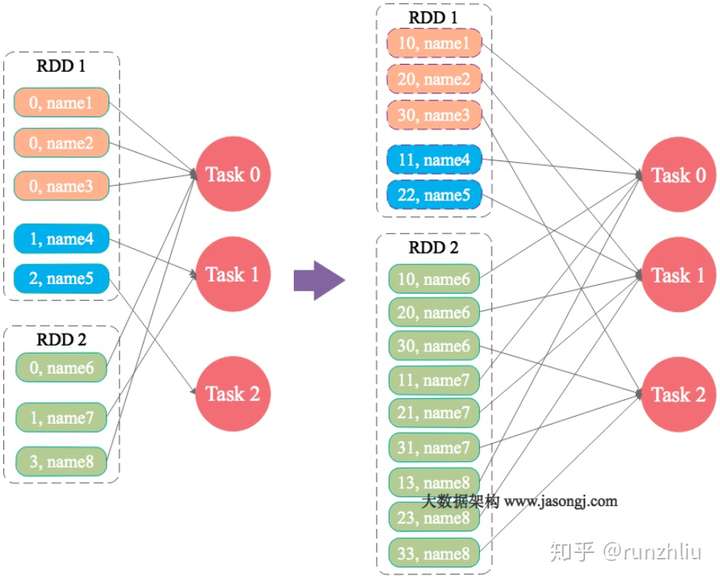
大表随机添加 N 种随机前缀,小表扩大 N 倍
如果出现数据倾斜的 Key 比较多,上一种方法将这些大量的倾斜 Key 分拆出来,意义不大(很难一个 Key 一个 Key 都加上后缀)。此时更适合直接对存在数据倾斜的数据集全部加上随机前缀,然后对另外一个不存在严重数据倾斜的数据集整体与随机前缀集作笛卡尔乘积(即将数据量扩大 N 倍),可以看到 RDD2 扩大了 N 倍了,再和加完前缀的大数据做笛卡尔积。
你所理解的 Spark 的 shuffle 过程?
Spark shuffle 处于一个宽依赖,可以实现类似混洗的功能,将相同的 Key 分发至同一个 Reducer上进行处理。
Shuffle Read 问题
在什么时候获取数据
当 Parent Stage 的所有 ShuffleMapTasks 结束后再 fetch。
边获取边处理还是一次性获取完再处理?
因为 Spark 不要求 Shuffle 后的数据全局有序,因此没必要等到全部数据 shuffle 完成后再处理,所以是边 fetch 边处理。
获取来的数据存放到哪里
刚获取来的 FileSegment 存放在 softBuffer 缓冲区,经过处理后的数据放在内存 + 磁盘上。
内存使用的是AppendOnlyMap ,类似 Java 的HashMap,内存+磁盘使用的是ExternalAppendOnlyMap,如果内存空间不足时,ExternalAppendOnlyMap可以将 records 进行 sort 后 spill(溢出)到磁盘上,等到需要它们的时候再进行归并
怎么获得数据的存放位置?
通过请求 Driver 端的 MapOutputTrackerMaster 询问 ShuffleMapTask 输出的数据位置。
触发 Shuffle 的操作
| 分类 | 操作 |
|---|---|
| repartition相关 | repartition、coalesce |
| *ByKey操作 | groupByKey、reduceByKey、combineByKey、aggregateByKey等 |
| join相关 | cogroup、join |
Spark有哪些聚合类的算子,我们应该尽量避免什么类型的算子?
在我们的开发过程中,能避免则尽可能避免使用 reduceByKey、join、distinct、repartition 等会进行 shuffle 的算子,尽量使用 map 类的非 shuffle 算子。这样的话,没有 shuffle 操作或者仅有较少 shuffle 操作的 Spark 作业,可以大大减少性能开销。
spark on yarn 作业执行流程,yarn-client 和 yarn cluster 有什么区别
Spark On Yarn 的优势
Spark 支持资源动态共享,运行于 Yarn 的框架都共享一个集中配置好的资源池
可以很方便的利用 Yarn 的资源调度特性来做分类·,隔离以及优先级控制负载,拥有更灵活的调度策略
Yarn 可以自由地选择 executor 数量
Yarn 是唯一支持 Spark 安全的集群管理器(Mesos???),使用 Yarn,Spark 可以运行于 Kerberized Hadoop 之上,在它们进程之间进行安全认证
yarn-client 和 yarn cluster 的异同
从广义上讲,yarn-cluster 适用于生产环境。而 yarn-client 适用于交互和调试,也就是希望快速地看到 application 的输出。
从深层次的含义讲,yarn-cluster 和 yarn-client 模式的区别其实就是 Application Master 进程的区别,yarn-cluster 模式下,driver 运行在 AM(Application Master)中,它负责向 YARN 申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉 Client,作业会继续在 YARN 上运行。然而 yarn-cluster 模式不适合运行交互类型的作业;而 yarn-client 模式下,Application Master 仅仅向 YARN 请求 executor,Client 会和请求的 container 通信来调度他们工作,也就是说 Client 不能离开。
Spark为什么快,Spark SQL 一定比 Hive 快吗
Spark SQL 比 Hadoop Hive 快,是有一定条件的,而且不是 Spark SQL 的引擎比 Hive 的引擎快,相反,Hive 的 HQL 引擎还比 Spark SQL 的引擎更快。其实,关键还是在于 Spark 本身快。
消除了冗余的 HDFS 读写
Hadoop 每次 shuffle 操作后,必须写到磁盘,而 Spark 在 shuffle 后不一定落盘,可以 cache 到内存中,以便迭代时使用。如果操作复杂,很多的 shufle 操作,那么 Hadoop 的读写 IO 时间会大大增加,也是 Hive 更慢的主要原因了。
消除了冗余的 MapReduce 阶段
Hadoop 的 shuffle 操作一定连着完整的 MapReduce 操作,冗余繁琐。而 Spark 基于 RDD 提供了丰富的算子操作,且 reduce 操作产生 shuffle 数据,可以缓存在内存中。
JVM 的优化
Hadoop 每次 MapReduce 操作,启动一个 Task 便会启动一次 JVM,基于进程的操作。而 Spark 每次 MapReduce 操作是基于线程的,只在启动 Executor 是启动一次 JVM,内存的 Task 操作是在线程复用的。每次启动 JVM 的时间可能就需要几秒甚至十几秒,那么当 Task 多了,这个时间 Hadoop 不知道比 Spark 慢了多少。
记住一种反例 考虑一种极端查询
Select month_id, sum(sales) from T group by month_id;这个查询只有一次 shuffle 操作,此时,也许 Hive HQL 的运行时间也许比 Spark 还快,反正 shuffle 完了都会落一次盘,或者都不落盘。
结论 Spark 快不是绝对的,但是绝大多数,Spark 都比 Hadoop 计算要快。这主要得益于其对 mapreduce 操作的优化以及对 JVM 使用的优化。
RDD, DAG, Stage怎么理解?
DAG
Spark 中使用 DAG 对 RDD 的关系进行建模,描述了 RDD 的依赖关系,这种关系也被称之为 lineage(血缘),RDD 的依赖关系使用 Dependency 维护。DAG 在 Spark 中的对应的实现为 DAGScheduler。
RDD
RDD 是 Spark 的灵魂,也称为弹性分布式数据集。一个 RDD 代表一个可以被分区的只读数据集。RDD 内部可以有许多分区(partitions),每个分区又拥有大量的记录(records)。
Rdd的五个特征
dependencies:建立 RDD 的依赖关系,主要 RDD 之间是宽窄依赖的关系,具有窄依赖关系的 RDD 可以在同一个 stage 中进行计算。
partition:一个 RDD 会有若干个分区,分区的大小决定了对这个 RDD 计算的粒度,每个 RDD 的分区的计算都在一个单独的任务中进行。
preferedlocations:按照“移动数据不如移动计算”原则,在 Spark 进行任务调度的时候,优先将任务分配到数据块存储的位置。
compute:Spark 中的计算都是以分区为基本单位的,compute 函数只是对迭代器进行复合,并不保存单次计算的结果。
partitioner:只存在于(K,V)类型的 RDD 中,非(K,V)类型的 partitioner 的值就是 None。
RDD 的算子主要分成2类,action 和 transformation。这里的算子概念,可以理解成就是对数据集的变换。action 会触发真正的作业提交,而 transformation 算子是不会立即触发作业提交的。每一个 transformation 方法返回一个新的 RDD。只是某些 transformation 比较复杂,会包含多个子 transformation,因而会生成多个 RDD。这就是实际 RDD 个数比我们想象的多一些的原因。通常是,当遇到 action 算子时会触发一个job的提交,然后反推回去看前面的 transformation 算子,进而形成一张有向无环图。
Stage
在 DAG 中又进行 stage 的划分,划分的依据是依赖是否是 shuffle 的,每个 stage 又可以划分成若干 task。接下来的事情就是 driver 发送 task 到 executor,executor 自己的线程池去执行这些 task,完成之后将结果返回给 driver。action 算子是划分不同 job 的依据。
RDD 如何通过记录更新的方式容错
RDD 的容错机制实现分布式数据集容错方法有两种
- 数据检查点
虽然RDD的血缘关系天然地可以实现容错,当RDD的某个分区数据失败或丢失,可以通过血缘关系重建。但是对于长时间迭代型应用来说,随着迭代的进行,RDD之间的血缘关系会越来越长,一旦在后续迭代过程中出错,则需要通过非常长的血缘关系去重建,势必影响性能。为此,RDD支持checkpoint将数据保存到持久化的存储中,这样就可以切断之前的血缘关系,因为checkpoint后的RDD不需要知道它的父RDDs了,它可以从checkpoint处拿到数据。
- 记录更新。
记录所有更新点的成本很高。所以,RDD只支持粗颗粒变换,即只记录单个块(分区)上执行的单个操作,然后创建某个 RDD 的变换序列(血统 lineage)存储下来;变换序列指,每个 RDD 都包含了它是如何由其他 RDD 变换过来的以及如何重建某一块数据的信息。因此 RDD 的容错机制又称“血统”容错。
RDD任务切分中间分为:Application、Job、Stage和Task
Application:初始化一个 SparkContext 即生成一个 Application
Job:一个 Action 算子就会生成一个 Job
Stage:根据RDD之间的依赖关系的不同将Job划分成不同的Stage,遇到一个宽依赖则划分一个Stage。
Task:Stage是一个TaskSet,将Stage划分的结果发送到不同的Executor执行即为一个Task。
注意:Application->Job(行动算子)->Stage-> Task(分区)每一层都是1对n的关系。
一个应用可以多次调用行动算子(Job),而每个作业中可以有多个阶段,同时在一个阶段中有多个分区(每个分区就是一个任务)
阶段划分数量 = 1 + shuffle数量
说说map和mapPartitions的区别
map 中的 func 作用的是 RDD 中每一个元素,而 mapPartitioons 中的 func 作用的对象是 RDD 的一整个分区。所以 func 的类型是 Iterator<T> => Iterator<T>,其中 T 是输入 RDD 的元素类型。
groupByKey和reduceByKey是属于什么算子
Transformation算子。因为 Action 输出的不再是 RDD 了,也就意味着输出不是分布式的,而是回送到 Driver 程序。以上两种操作都是返回 RDD,所以应该属于 Transformation。
Spark支持的3种集群管理器
Standalone 模式
资源管理器是 Master 节点,调度策略相对单一,只支持先进先出模式。
Hadoop Yarn 模式
资源管理器是 Yarn 集群,主要用来管理资源。Yarn 支持动态资源的管理,还可以调度其他实现了 Yarn 调度接口的集群计算,非常适用于多个集群同时部署的场景,是目前最流行的一种资源管理系统。
Apache Mesos
Mesos 是专门用于分布式系统资源管理的开源系统,与 Yarn 一样是 C++ 开发,可以对集群中的资源做弹性管理。
Spark提供的两种共享变量
Spark 程序的大部分操作都是 RDD 操作,通过传入函数给 RDD 操作函数来计算,这些函数在不同的节点上并发执行,内部的变量有不同的作用域,不能相互访问,有些情况下不太方便。
广播变量,是一个只读对象,在所有节点上都有一份缓存,创建方法是 SparkContext.broadcast()。创建之后再更新它的值是没有意义的,一般用 val 来修改定义。
计数器,只能增加,可以用计数或求和,支持自定义类型。创建方法是 SparkContext.accumulator(V, name)。只有 Driver 程序可以读这个计算器的变量,RDD 操作中读取计数器变量是无意义的。




